How to Benchmark Apache Hive on Hadoop Node using ‘hive-testbench’


Audio : Listen to This Blog.
Apache Hive is a data warehouse software project built on top of Apache Hadoop for the querying of large data systems in the open-source Hadoop platform.
Hive gives a SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
The three important features for which Hive is deployed are
1) Data summarization
2) Data analysis
3) Data query
The query language, exclusively supported by Hive, is HiveQL. This language translates SQL-like queries into MapReduce jobs for deploying them on Hadoop nodes.
Install Hadoop
Step 1:
I’ve built a virtual machine with CentOS 7, with below software specifications:
vSphere web client: Version 6.7
Hypervisor: VMware ESXi, 6.7.0,
Datastore Backend: SAN volume connected via FC
Datastore Type: VMFS6
VM version: 14
Software versions used:
- Java version “1.8.0_221”
- Hadoop version: 3.2.1
- Hive version: 3.1.2
Step 2: Prerequisites:
- Prepare a new VM with CentOS7 installed.
- Make sure VM have proper IP and HOSTNAME entries in /etc/hosts.
- Setup Passwordless SSH on VM using ssh-keygen (copy id_rsa.pub to /root/.ssh/authorized_keys on the same hosts)
- Disable IPv6 by editing /etc/sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1
Step 3: Install Java on CentOS7
Download Tar or RPM file of Java 8: tar -xvf jdk-8u221-linux-x64.tar.gz mkdir /usr/java mv jdk1.8.0_221/ /usr/java/ alternatives --install /usr/bin/java java /usr/java/jdk1.8.0_221/bin/java 2 alternatives --install /usr/bin/javaws javaws /usr/java/jdk1.8.0_221/bin/javaws 2 alternatives --install /usr/bin/javac javac /usr/java/jdk1.8.0_221/bin/javac 2 alternatives --install /usr/bin/jar jar /usr/java/jdk1.8.0_221/bin/jar 2 alternatives --install /usr/bin/jps jps /usr/java/jdk1.8.0_221/bin/jps 2 [root@hive ~]# java -version java version "1.8.0_221" Java(TM) SE Runtime Environment (build 1.8.0_221-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode) Update /etc/profile: echo "" >> /etc/profile echo "## Setting JAVA_HOME and PATH for all USERS ##" >> /etc/profile echo "export JAVA_HOME=/usr/java/jdk1.8.0_221" >> /etc/profile echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile source /etc/profile
Step 4: Download Hadoop 3.2.1 and extract it to /opt/ directory
wget http://mirrors.estointernet.in/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz tar -xvf hadoop-3.2.1.tar.gz Update /etc/profile: echo "" >> /etc/profile echo "### HADOOP Variables ###" >> /etc/profile echo "export HADOOP_HOME=/opt/hadoop-3.2.1" >> /etc/profile echo "export HADOOP_MAPRED_HOME=\$HADOOP_HOME" >> /etc/profile echo "export HADOOP_COMMON_HOME=\$HADOOP_HOME" >> /etc/profile echo "export HADOOP_HDFS_HOME=\$HADOOP_HOME" >> /etc/profile echo "export YARN_HOME=\$HADOOP_HOME" >> /etc/profile echo "export HADOOP_COMMON_LIB_NATIVE_DIR=\$HADOOP_HOME/lib/native" >> /etc/profile echo "export PATH=\$PATH:\$HADOOP_HOME/sbin:\$HADOOP_HOME/bin" >> /etc/profile source /etc/profile
Step 5: Setting up Hadoop Environment
mkdir -p /data/hadoop-data/nn mkdir -p /data/hadoop-data/snn mkdir -p /data/hadoop-data/dn mkdir -p /data/hadoop-data/mapred/system mkdir -p /data/hadoop-data/mapred/local edit $HADOOP_HOME/etc/hadoop/hadoop-env.sh file and set JAVA_HOME environment variable export JAVA_HOME=/usr/java/jdk1.8.0_221/
Step 6: Edit Hadoop XML Configuration files
hdfs-site.xml
dfs.replication
1
dfs.name.dir
file:///data/hadoop-data/nn
dfs.data.dir
file:///data/hadoop-data/dn
dfs.namenode.checkpoint.dir
file:///data/hadoop-data/snn
core-site.xml
fs.default.name
hdfs://hive:9000
Note: hive is the hostname of VM
mapred-site.xml
yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1 mapreduce.map.env HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1 mapreduce.reduce.env HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1 mapreduce.framework.name yarn
yarn-site.xml
yarn.resourcemanager.hostname
hive
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
Step 7: We need to format Hadoop NameNode using the below command prior tobefore starting the Hadoop cluster.
hdfs namenode -format Sample output: WARNING: /home/hadoop/hadoop/logs does not exist. Creating. 2018-05-02 17:52:09,678 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hive/xxx.xxx.xxx.xxx STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.2.1 ... ... ... 2018-05-02 17:52:13,717 INFO common.Storage: Storage directory /opt/hadoop/hadoopdata/hdfs/namenode has been successfully formatted. 2018-05-02 17:52:13,806 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2018-05-02 17:52:14,161 INFO namenode.FSImageFormatProtobuf: Image file /opt/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds . 2018-05-02 17:52:14,224 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2018-05-02 17:52:14,282 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hive/xxx.xxx.xxx.xxx ************************************************************/
Step 8: Commands for starting and stopping Hadoop Cluster
cd $HADOOP_HOME/sbin/ ./start-dfs.sh ./start-yarn.sh If you’rer using a root user to start hadoop on VM, then following commands needs to be executed as root user prior to the above commands. export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root"
Step 9: Access Hadoop Services in Browser
- Hadoop NameNode started on port 9870 default. Access your server on port 9870 in your favorite web browser.
- Now access port 8042 for getting the information about the cluster and all applications.
- Access port 9864 to get details about your Hadoop node.
Port Filtering in Firewall by updating below entries in /etc/sysconfig/iptables file. Append below lines in /etc/sysconfig/iptables file -A INPUT -m state --state NEW -m tcp -p tcp --dport 9870 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 8042 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 9864 -j ACCEPT (Or) sudo service iptables stop - To disable all the port Now you can access Hadoop Services in Web Browser.
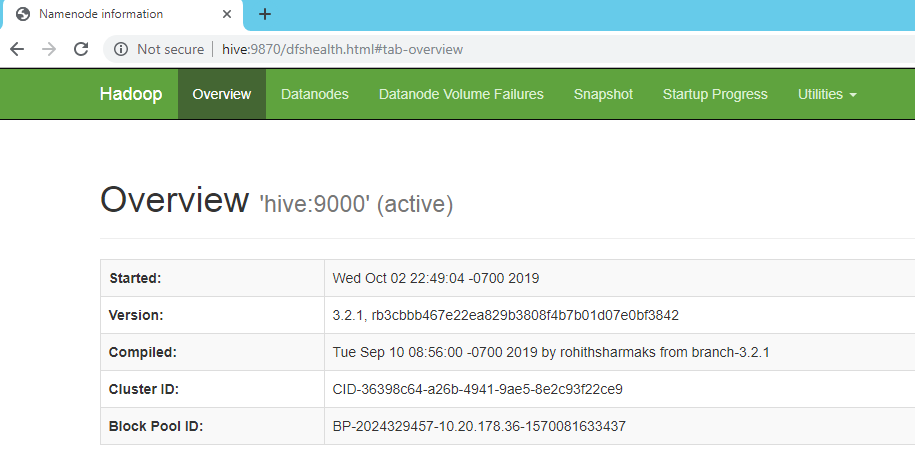
Install Apache Hive:
Step 1: Download the appropriate version of Hive & Extract it.
wget http://apachemirror.wuchna.com/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz tar -xvf apache-hive-3.1.2-bin.tar.gz Update /etc/profile echo "### Hive Variables ###" >> /etc/profile cd /opt/hadoop-3.2.1/bin/hadoop echo "export HADOOP=/opt/hadoop-3.2.1/bin/hadoop" >> /etc/profile echo "export HIVE_HOME=/opt/apache-hive-3.1.2-bin" >> /etc/profile echo "export PATH=\$HIVE_HOME/bin:\$PATH" >> /etc/profile source /etc/profile
Step 2: Create hive directories on HDFS (Hadoop FileSystem)
1) Start hadoop if not started yet: cd $HADOOP_HOME/sbin ./start-all.sh 2) Check if all below 5 daemons are active and running using the command JPS: jps Hadoop daemons: ResourceManager SecondaryNameNode DataNode NodeManager NameNode 3) Create directories: hdfs dfs -mkdir -p /user/hive/warehouse hdfs dfs -mkdir /tmp hdfs dfs -chmod g+w /tmp hdfs dfs -chmod g+w /user/hive/warehouse 4) Inform Hive about home directory of Hadoop: vi $HIVE_HOME/bin/hive-config.sh export HADOOP_HOME=/opt/hadoop-3.2.1
Step 3: Open hive shell
[root@hive ~]# $HIVE_HOME/bin/hive which: no hbase in (/opt/apache-hive-3.1.2-bin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_221/bin:/opt/hadoop-3.2.1/sbin:/opt/hadoop-3.2.1/bin:/root/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Hive Session ID = eb69b2ba-b509-4ae6-94f9-b7b82281b587 Logging initialized using configuration in jar:file:/opt/apache-hive-3.1.2-bin/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true hive>
Install hive-testbench
A testbench for experimenting with Apache Hive at any data scale.
Overview: The hive-testbench is a data generator and set of queries that lets you experiment with Apache Hive at scale. The testbench allows you to experience base Hive performance on large datasets, and gives an easy way to see the impact of Hive tuning parameters and advanced settings.
hive-testbench comes with data generators and sample queries based on both the TPC-DS and TPC-H benchmarks.
Download hive-testbench-hdp3.zip and extract it,
[root@hive hive-testbench-hdp3]# ls -l
total 5116
drwxr-xr-x. 6 root root 107 Oct 3 04:22 apache-maven-3.0.5
-rw-r--r--. 1 root root 5144659 Oct 3 04:22 apache-maven-3.0.5-bin.tar.gz
drwxr-xr-x. 4 root root 41 Jun 21 14:11 ddl-tpcds
drwxr-xr-x. 4 root root 45 Jun 21 14:11 ddl-tpch
-rw-r--r--. 1 root root 22213 Oct 3 06:00 derby.log
drwxr-xr-x. 5 root root 133 Oct 3 06:00 metastore_db
-rw-r--r--. 1 root root 4550 Jun 21 14:11 README.md
-rwxr-xr-x. 1 root root 1887 Jun 21 14:11 runSuite.pl
drwxr-xr-x. 3 root root 4096 Oct 3 05:59 sample-queries-tpcds
drwxr-xr-x. 2 root root 4096 Jun 21 14:11 sample-queries-tpch
drwxr-xr-x. 2 root root 71 Jun 21 14:11 settings
drwxr-xr-x. 2 root root 4096 Jun 21 14:11 spark-queries-tpcds
-rwxr-xr-x. 1 root root 1111 Jun 21 14:11 tpcds-build.sh
drwxr-xr-x. 5 root root 115 Oct 3 04:22 tpcds-gen
-rwxr-xr-x. 1 root root 3725 Jun 21 14:11 tpcds-setup.sh
-rwxr-xr-x. 1 root root 1107 Jun 21 14:11 tpch-build.sh
drwxr-xr-x. 5 root root 91 Jun 21 14:11 tpch-gen
-rwxr-xr-x. 1 root root 2448 Jun 21 14:11 tpch-setup.sh
In addition to Hadoop and Hive, before you begin ensure gcc is installed on VM
sudo yum group install "Development Tools"
sudo yum install man-pages
[root@hive ~]# gcc --version
gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39)
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Decide which test suite(s) you want to use
“hive-testbench comes with data generators and sample queries based on both the TPC-DS and TPC-H benchmarks”
Compile and package the appropriate data generator (TPC-DS or TPC-H)
For TPC-DS, run ./tpcds-build.sh - downloads, compiles and packages the TPC-DS data generator.
For TPC-H, run ./tpch-build.sh - downloads, compiles and packages the TPC-H data generator
Generate and load the data
Example:
Build 1 TB of TPC-DS data: ./tpcds-setup.sh 1000
Build 1 TB of TPC-H data: ./tpch-setup.sh 1000
Sample tests:
[root@hive hive-testbench-hdp3]# ./tpcds-setup.sh 10
2019-10-03 04:38:21,137 INFO mapreduce.Job: The url to track the job: http://hive:8088/proxy/application_1570081767440_0002/
2019-10-03 04:38:21,138 INFO mapreduce.Job: Running job: job_1570081767440_0002
2019-10-03 04:38:27,255 INFO mapreduce.Job: Job job_1570081767440_0002 running in uber mode : false
2019-10-03 04:38:27,256 INFO mapreduce.Job: map 0% reduce 0%
2019-10-03 04:42:18,571 INFO mapreduce.Job: map 10% reduce 0%
2019-10-03 04:42:21,595 INFO mapreduce.Job: map 20% reduce 0%
2019-10-03 04:42:28,713 INFO mapreduce.Job: map 30% reduce 0%
2019-10-03 04:42:34,839 INFO mapreduce.Job: map 40% reduce 0%
2019-10-03 04:42:39,900 INFO mapreduce.Job: map 50% reduce 0%
2019-10-03 04:42:46,952 INFO mapreduce.Job: map 60% reduce 0%
2019-10-03 04:45:56,411 INFO mapreduce.Job: map 70% reduce 0%
2019-10-03 04:46:10,552 INFO mapreduce.Job: map 80% reduce 0%
2019-10-03 04:46:15,568 INFO mapreduce.Job: map 90% reduce 0%
2019-10-03 04:50:25,305 INFO mapreduce.Job: map 100% reduce 0%
2019-10-03 04:50:26,311 INFO mapreduce.Job: Job job_1570081767440_0002 completed successfully
2019-10-03 04:50:26,408 INFO mapreduce.Job: Counters: 34
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=2278570
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=4349
HDFS: Number of bytes written=12194709083
HDFS: Number of read operations=297
HDFS: Number of large read operations=0
HDFS: Number of write operations=183
HDFS: Number of bytes read erasure-coded=0
Job Counters
Killed map tasks=5
Launched map tasks=14
Other local map tasks=14
Total time spent by all maps in occupied slots (ms)=3202768
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=3202768
Total vcore-milliseconds taken by all map tasks=3202768
Total megabyte-milliseconds taken by all map tasks=3279634432
Map-Reduce Framework
Map input records=10
Map output records=0
Input split bytes=1030
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=12320
CPU time spent (ms)=366120
Physical memory (bytes) snapshot=4094967808
Virtual memory (bytes) snapshot=28064542720
Total committed heap usage (bytes)=3325034496
Peak Map Physical memory (bytes)=465870848
Peak Map Virtual memory (bytes)=2856607744
File Input Format Counters
Bytes Read=3319
File Output Format Counters
Bytes Written=0
TPC-DS text data generation complete.
Loading text data into external tables.
Optimizing table date_dim (1/24).
Optimizing table catalog_returns (23/24).
Optimizing table inventory (24/24).
Loading constraints
Data loaded into database tpcds_bin_partitioned_orc_10.
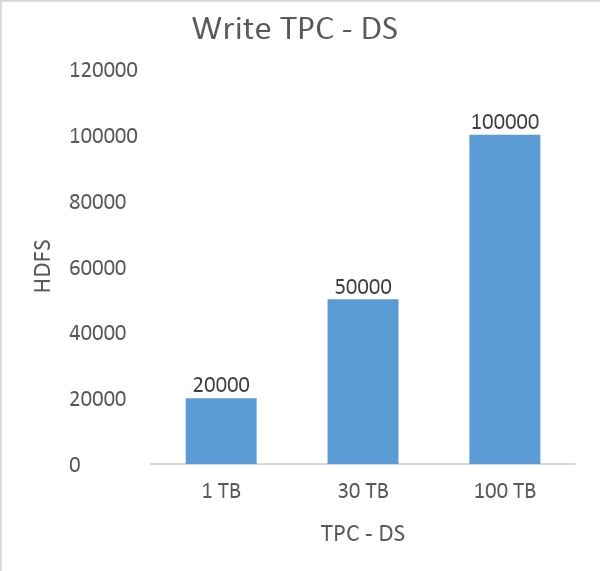
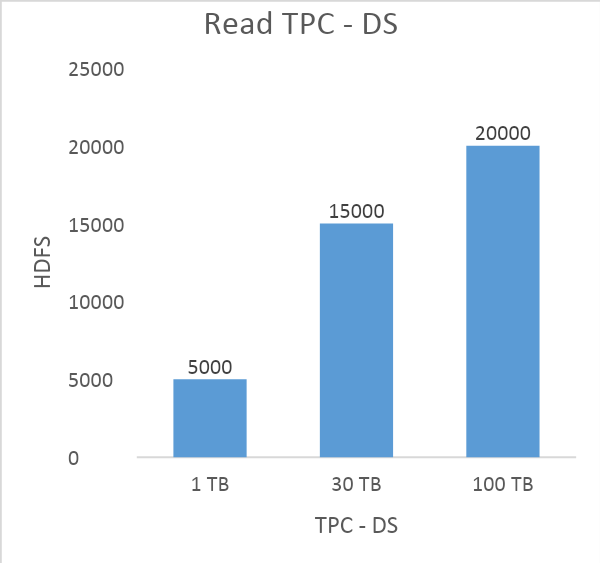
References:
https://github.com/hortonworks/hive-testbench
https://github.com/abzetdin-adamov/install-hive-on-centos-7