Is there an Alternative for Hadoop ?


Audio : Listen to This Blog.
Hadoop
Using big data technologies for your business is a really an attractive thing and Hadoop makes it even more appealing nowadays. Hadoop is a massively scalable data storage platform that is used as a foundation for many big data projects. Hadoop is powerful, however it has a steep learning curve in terms of time and other resources. It can be a game changer for companies if Hadoop is being applied the right way. Hadoop will be around for a longer time and for good reason as Hadoop can solve even fewer problems.
For large corporations that routinely crunch large amounts of data using MapReduce, Hadoop is still a great choice. For research, experimentation, everyday data mugging.
Apache Hadoop, the open-source framework for storing and analyzing big data, will be embraced by analytics vendors over the next two years as organizations seek out new ways to derive value from their unstructured data, according to a new research report from Gartner.
Few alternatives of Hadoop
As a matter of fact, there are many ways to store data in a structured way which stand as an Alternative for Hadoop namely BashReduce, Disco Project, Spark, GraphLab and the list goes on. Each one of them is unique in their own way. If GraphLab was developed and designed for use in machine learning which is focused to make the design and implementation of efficient and correct parallel machine learning algorithms easier, then Spark is one of the newest players in the MapReduce field which stands as a purpose to make data analytics fast to write and run.
Conclusion:
Despite all these Alternatives, Why Hadoop?
One word: HDFS. For a moment, assume you could bring all of your files and data with you everywhere you go. No matter what system, or type of system, you log in to, your data is intact waiting for you. Suppose you find a cool picture on the Internet. You save it directly to your file store and it goes everywhere you go. HDFS gives users the ability to dump very large data sets (usually log files) to this distributed file system and easily access it with tools, namely Hadoop. Not only does HDFS store a large amount of data, it is fault tolerant. Losing a disk, or a machine, typically does not spell disaster for your data. HDFS has become a reliable way to store data and share it with other open-source data analysis tools. Spark can read data from HDFS, but if you would rather stick with Hadoop, you can try to spice it up.
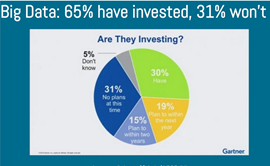
Below trend shows the percent of Hadoop adoption:
Research firm projects that 65 percent of all “packaged analytic applications with advanced analytics” capabilities will come prepackaged with the Hadoop framework by 2015. The spike in Hadoop adoption largely will be spurred by an organizations’ need to analyze the massive amounts of unstructured data being produced from nontraditional data sources such as social media. Source: Gartner
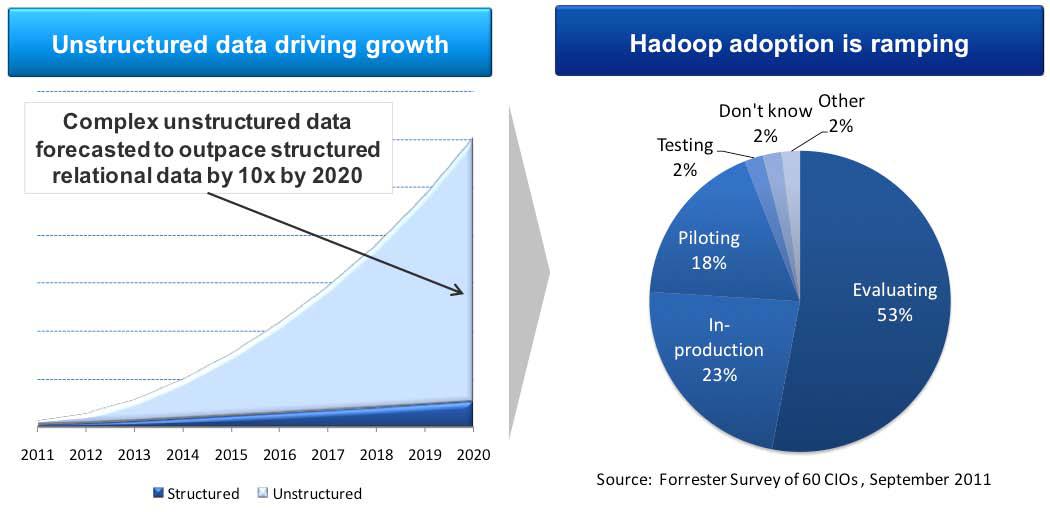
“It doesn’t take a clairvoyant — or in this case, a research analyst — to see that ‘big data’ is becoming (if it isn’t already, perhaps) a major buzzword in security circles. Much of the securing of big data will need to be handled by thoroughly understanding the data and its usage patterns. Having the ability to identify, control access to, and — where possible — mask sensitive data in big data environments based on policy is an important part of the overall approach.”
Ramon Krikken
Research VP, Security and Risk Management Strategies Analyst at Gartner
“Hadoop is not a single entity, it’s a conglomeration of multiple projects, each addressing a certain niche within the Hadoop ecosystem such as data access, data integration, DBMS, system management, reporting, analytics, data exploration and much, much more,” – Forrester analyst Boris Evelson.
Forrester Research, Inc. views Hadoop as “the open source heart of Big Data”, regarding it as “the nucleus of the next-generation EDW [enterprise data warehouse] in the cloud,” and has published its first ever The Forrester Wave: Initiative Hadoop Solutions report (February 2, 2012).
Hadoop Streaming is an easy way to avoid the monolith of Vanilla Hadoop without leaving HDFS, and allows the user to write map and reduce functions in any language that supports writing to stdout, and reading from stdin. Choosing a simple language such as Python for Streaming allows the user to focus more on writing code that processes data rather than software engineering.
The bottom line is that Hadoop is the future of the cloud EDW. Its footprint in companies’ core EDW architectures is likely to keep growing throughout this decade. The roles that Hadoop is likely to assume in EDW strategy are the dominant applications.
So? What is your experience with big data? Please share with us in the comments section.