8 Steps To Foolproof Your Big Data Testing Cycle


Audio : Listen to This Blog.
Big Data refers to all the data that is generated across the globe at an unprecedented rate. This data could be either structured or unstructured. Comprehending this information and disentangling the different examples, uncovering the various patterns, and revealing unseen connections within the vast sea of data becomes critical and a massively compensating undertaking in reality. Better data leads to better decision making, and an improved way to strategize for organizations, irrespective of their size. The best ventures of tomorrow will be the ones that can make sense of all data at extremely high volumes and speeds to capture newer markets and client base.
Why require Big Data Testing?
With the presentation of Big Data, it turns out to be especially vital to test the enormous information framework with the utilization of suitable information accurately. If not tried appropriately, it would influence the business altogether; thus, automation becomes a key part of Big Data Testing. Enormous Data Testing whenever done inaccurately will make it extremely hard to comprehend the blunder, how it happened and the likely arrangement with alleviation steps could take quite a while along these lines bringing about mistaken/missing information, and adjusting it is again a colossal test so that present streaming information isn’t influenced. As information is critical, it is prescribed to have a relevant component with the goal that information isn’t lost/debased and proper mechanism should be used to handle failovers
Big Data has certain characteristics and hence is defined using 4Vs, namely:
- Volume: is the measure of information that organizations can gather. It is huge and consequently, the volume of the information turns into a basic factor in Big Data Analytics.
- Velocity: the rate at which new information is being created, on account of our reliance on the web, sensors, machine-to-machine information is likewise imperative to parse Big Data conveniently.
- Variety: the information that is produced is heterogeneous; as in it could be in different types like video, content, database, numeric, sensor data and so on and consequently understanding the kind of Big Data is a key factor to unlocking its potential.
- Veracity: knowing whether the information that is accessible is originating from a believable source is of most extreme significance before unraveling and executing Big Data for business needs.
Here is a concise clarification of how precisely organizations are using Big Data:
When Big Data is transformed into pieces of data then it turns out to be quite direct for most business endeavors as it comprehends what their clients need, what items are quick moving, what are the desires for the clients from the client benefit, how to accelerate an opportunity to advertise, approaches to lessen expenses, and strategies to assemble economies of scale in an exceedingly productive way. Thus Big Data distinctively leads to big-time benefits for organizations and hence naturally there is such a huge amount of interest in it from all around the world.
Testing Big Data:
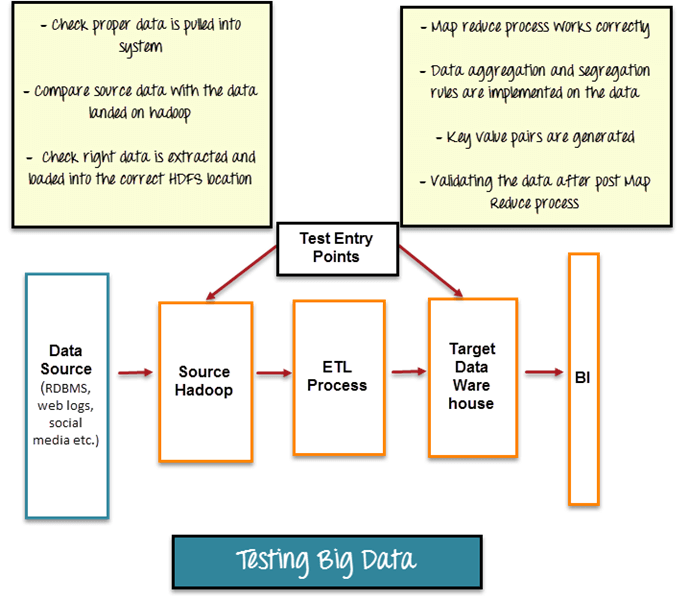
Source: Guru99.com
Let us have a look at the scenarios for which Big Data Testing can be used in the Big Data components: –
1. Data Ingestion: –
- This progression is considered as pre-Hadoop arrange where information is created from different sources and information streams into HDFS. In this progression, the analyzers check that information is removed legitimately and information is stacked into HDFS.
- Ensure appropriate information from different sources is ingested; for example, every required datum is ingested according to its characterized mapping; and information with non-coordinating pattern is not to be ingested. Information which has not coordinated with diagram ought to be put away for details stating the reason.
- Comparison of source data with data ingested to simply validate that correct data is pushed.
- Verify that correct data files are generated and loaded into HDFS correctly into desired location.
2. Data Processing: –
- This progression is utilized for approving Map-Reduce employments. Map-Reduce is a concept used for condensing large amount of data into aggregated data. The information ingested is handled utilizing execution of Map-Reduce employments which gives wanted outcomes. In this progression, the analyzer confirms that ingested data is prepared utilizing Map-Reduce employments and approve whether business rationale is actualized accurately.
Data Storage: –
- This progression is utilized for putting away yield information in HDFS or some other stockpiling framework, (for example, Data Warehouse). In this progression the analyzer checks that yield information is effectively produced and stacked into capacity framework.
- Validate information is amassed post Map-Reduce Jobs.
- Verify that right information is stacked into capacity framework and dispose of any middle of the road information which is available.
- Verify that there is no information defilement by contrasting yield information and HDFS (or any capacity framework) information.
The other types of testing scenarios a Big Data Tester can do is: –
4. Check whether legitimate ready instruments are actualized, for example, Mail on alarm, sending measurements on Cloud watch and so forth.
5. Check whether exceptions or mistakes are shown legitimately with suitable special case message so tackling a blunder turns out to be simple.
6. Performance testing to test the distinctive parameters to process an arbitrary lump of vast information and screen parameters, for example, time taken to finish Map-Reduce Jobs, memory use, circle use and different measurements as required.
7. Integration testing for testing complete work process specifically from information ingestion to information stockpiling/representation.
8. Architecture testing for testing that Hadoop is exceptionally accessible all the time and failover administrations are legitimately executed to guarantee information is handled even if there should arise an occurrence of disappointment of hubs.
Data Storage – HDFS (Hadoop Distributed File System), Amazon S3, HBase.
Note: – For testing it is very important to generate data that covers various test scenarios (positive and negative). Positive test scenarios cover scenarios which are directly related to the functionality. Negative test scenarios cover scenarios which do not have direct relation with the desired functionality.
Tools used in Big Data Testing
Data Ingestion – Kafka, Zookeeper, Sqoop, Flume, Storm, Amazon Kinesis.
Data Processing – Hadoop (Map-Reduce), Cascading, Oozie, Hive, Pig.