Driving Success in Complex IT Settings with the Power of Observability

Audio : Listen to This Blog.
In today’s rapidly evolving digital landscape, businesses increasingly rely on complex IT infrastructures to deliver their products and services. IT teams face enormous pressure to track and respond to conditions and issues across multi-cloud environments as these infrastructures grow in scale and complexity.
To overcome this challenge, IT operations, DevOps, and Site Reliability Engineering (SRE) teams are turning to observability — deep insights into the inner workings of these intricate computing environments.
But what exactly is observability? Why is it crucial for organizations, and how can it help them achieve their goals? Here are a few statistics supporting the claim that observability is the next big thing if it isn’t already.
- The observability market is forecasted to reach $2B by 2026, growing from $278M in 2022.
- 91% of IT decision-makers see observability as critical at every stage of the software lifecycle.
- Advanced observability deployments can cut downtime costs by 90 percent.
Source: CDInsights
In this article, let’s explore the concept of observability, its importance, and its benefits.
Decoding the Mystique: Observability
In terms of IT and cloud computing, observability pertains to the capacity to ascertain a system’s existing status—drawing insights from its produced data, encompassing a variety of facets, including logs, metrics, and traces. It relies on telemetry derived from instrumentation across various endpoints and services within multi-cloud environments. Every component records every activity, from hardware and software to cloud infrastructure, containers, open-source tools, and microservices.
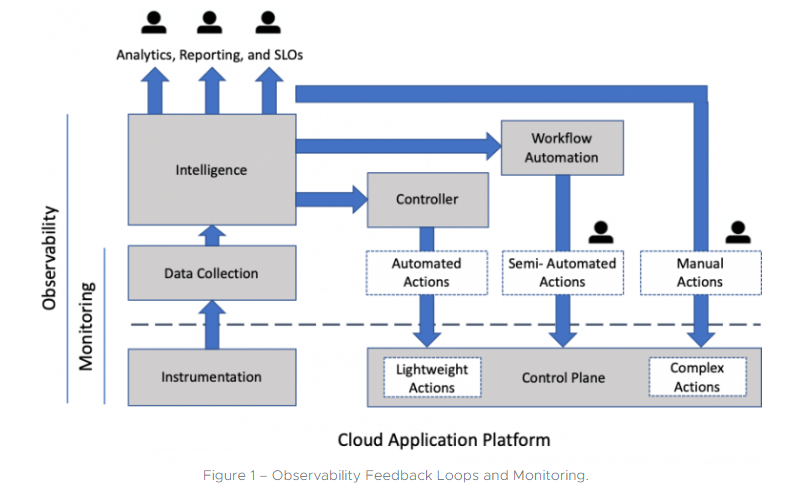
Source: VMware
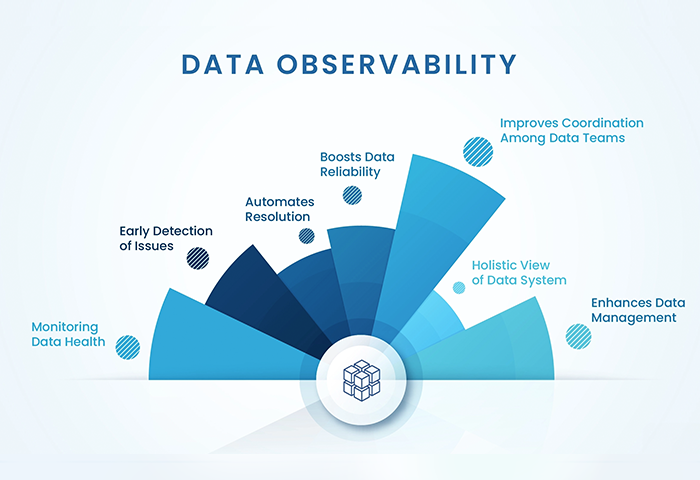
Observability aims to comprehensively understand what’s happening across these environments and technologies, enabling teams to detect and resolve issues promptly, ensuring efficient and reliable systems and satisfied customers. With the increasing complexity of cloud-native environments and the challenges of pinpointing root causes for failures or anomalies, observability has become a critical capability for organizations.
Observability vs. Monitoring: Delineating the Differences
While observability and monitoring are related concepts that can complement each other, they are fundamentally different. Monitoring typically involves preconfiguring dashboards to alert you to anticipated performance issues. However, this approach assumes that you can predict potential problems. In dynamic and complex cloud-native environments, it is challenging to foresee all the potential issues.
Observability provides a more flexible approach. By fully instrumenting an environment and collecting observability data, you can explore what’s happening and quickly identify the root causes of unforeseen issues.
| Aspect | Observability | Monitoring |
| Focus | Emphasizes understanding and insights | Focuses on tracking predefined metrics |
| Scope | Holistic view of system behavior | Specific metrics and thresholds |
| Data Collection | Captures raw data and events | Collects predefined metrics |
| Flexibility | Adapts to changing and unknown issues | Designed for known scenarios |
| Analysis Approach | Analyzes patterns and correlations | Identifies deviations from norms |
| Use Case | Complex, dynamic, and unpredictable | Routine health checks and alerts |
Observability allows you to uncover “unknown unknowns” by continuously understanding new problems as they arise.
Leveraging Observability: A New Way to Enhance IT and Business Operations
Cloud environments are dynamic and constantly changing, making predicting, and monitoring all potential problems challenging. Observability addresses this challenge by continuously and automatically understanding new issues as they arise. Additionally, observability is a critical capability of artificial intelligence for IT operations (AIOps), allowing organizations to automate processes throughout the DevSecOps life cycle and gain reliable answers for monitoring, testing, continuous delivery, application security, and incident response.
Observability provides valuable insights into the business impact of digital services. Organizations can optimize conversions, validate software releases against business goals, measure user experience outcomes, and prioritize business decisions based on real-time information by collecting and analyzing observability data.
Benefits of Observability
Observability brings powerful benefits to IT teams, organizations, and end-users alike. Let’s explore some of the key use cases facilitated by observability:
1. Application Performance Monitoring
Observability enables organizations to gain end-to-end visibility into application performance issues, including those arising from cloud-native and microservices environments. With advanced observability solutions, teams can automate processes, increasing efficiency and innovation among Operations and Applications teams.
2. DevSecOps and Site Reliability Engineering (SRE)
Observability is not just about implementing advanced tools; it is a foundational property of an application and its supporting infrastructure. By designing systems to be observable, architects and developers empower DevSecOps and SRE teams to leverage and interpret observability data throughout the software delivery life cycle, resulting in better, more secure, and resilient applications.
3. Infrastructure, Cloud, and Kubernetes Monitoring
Observability enhances the context for infrastructure and operations (I&O) teams, improving application uptime and performance. It reduces the time required to pinpoint and resolve issues, detects cloud latency issues, optimizes cloud resource utilization, and streamlines the administration of Kubernetes environments and modern cloud architectures.
4. End-User Experience
A positive user experience is critical for a company’s reputation and revenue. Observability allows organizations to identify and resolve issues before users notice them, improving customer satisfaction and retention. By gaining real-time insight into the end-user experience, organizations can design better user experiences based on immediate feedback.
5. Business Analytics
Observability enables organizations to combine business context with application analytics and performance data to understand real-time business impact. It helps improve conversion optimization, ensure software releases meet business goals, and adhere to internal and external service level agreements (SLAs).
Making a System Observable
To achieve observability, collecting and analyzing logs, metrics, and distributed traces is essential—the three pillars of observability. However, observing raw telemetry from backend applications alone does not comprehensively understand system behavior. It is crucial to augment telemetry collection with user experience data to eliminate blind spots.
Logs are structured or unstructured records of specific events, metrics are values represented as counts or measures calculated over time, and distributed tracing displays the activity of a transaction or request as it flows through applications, showing how services connect. Additionally, user experience data provides the outside-in perspective of a specific digital experience, allowing organizations to understand the end-user’s perspective.
Overcoming Challenges of Observability
Although there are numerous advantages of employing observability, it also introduces complexities, notably in cloud-native ecosystems. Understanding the technology can help in navigating these obstacles. Here, we address a few prevalent difficulties and their potential solutions:
1. Data Silos
Multiple agents, disparate data sources, and siloed monitoring tools create challenges in understanding interdependencies across applications, multiple clouds, and digital channels. Organizations should strive to integrate these data sources and enhance observability across the system.
2. Volume, Velocity, Variety, and Complexity
Modern cloud environments generate vast amounts of telemetry data at high velocities and in diverse formats. Managing and making sense of this data can be overwhelming. Organizations should invest in solutions that can effectively handle observability data’s volume, velocity, variety, and complexity.
3. Manual Instrumentation and Configuration
Instrumenting and configuring observability for every new component or agent can be time-consuming and error prone. Automation is crucial in reducing the burden on IT resources and ensuring consistent observability across the system.
4. Lack of Pre-production Observability
Understanding how real users interact with applications and infrastructure before deployment is essential. Load testing in pre-production environments can provide some insights, but organizations should strive to observe and understand the impact on end-users before pushing code into production.
5. Troubleshooting
Troubleshooting issues across multiple teams and tools can take time and effort. Organizations should streamline the troubleshooting process by leveraging observability solutions that provide actionable insights and facilitate team collaboration.
The Power of a Single Source of Truth
Organizations need a single source of truth to achieve complete observability and effectively pinpoint the root causes of performance issues. A single platform that can consolidate and analyze data from various sources with artificial intelligence (AI) can provide immediate and accurate insights into system health.
A single source of truth enables teams to turn terabytes of telemetry data into actionable answers, gain crucial contextual insights into the infrastructure, and work collaboratively to troubleshoot and resolve issues faster. Organizations can streamline their observability efforts and drive innovation by eliminating the need to navigate multiple tools and vendors.
Making Observability Actionable and Scalable
Observability must be implemented to allow resource-constrained teams to act upon the vast amount of telemetry data collected in real time. Here are some strategies to make observability actionable and scalable:
1. Understand Context and Topology
Instrumenting systems to create an understanding of relationships between components in highly dynamic environments is crucial. Rich context metadata enables real-time topology maps, providing an understanding of causal dependencies vertically throughout the stack and horizontally across services, processes, and hosts.
2. Implement Continuous Automation
Automate the discovery, instrumentation, and baselining of system components on an ongoing basis. This shift from manual configuration work to automation allows teams to focus on innovation and prioritize understanding the most critical aspects of observability.
3. Establish True AIOps
Use AI-driven fault-tree analysis and code-level visibility to pinpoint anomalies’ root causes automatically. Causation-based AI can detect unusual change points and unknown unknowns, enabling faster and more accurate responses from DevOps and SRE teams.
4. Foster an Open Ecosystem
Extend observability to include external data sources, such as OpenTelemetry. Open-source projects like OpenTelemetry enhance telemetry collection and ingestion for cloud-native applications, providing a consistent understanding of application health across multiple environments.
Embracing Observability for Cloud Success
Building comprehensive observability into your cloud infrastructure from the start is essential. By implementing observability early on, disambiguating between application and cloud issues, defining an observability strategy beyond monitoring, and regularly cleaning up observability artifacts, organizations can maximize the benefits of observability in their cloud journey.
The combination of monitoring, logging, tracing, profiling, debugging, and other observability systems empowers IT teams to navigate the challenges of modern cloud-native architectures. Embrace observability as a core principle in your IT infrastructure and unlock the full potential of your systems.