Ignite Business Acceleration and Tap into the Might of Distributed Storage Systems


Audio : Listen to This Blog.
Managing and storing massive amounts of data has become critical for organizations in today’s digital era. Traditional centralized storage systems often need help to cope with modern applications’ scale, performance, and fault tolerance demands. This is where distributed storage systems come into play. In this blog, we will delve into the inner workings of distributed storage systems, exploring the types of data they can handle, their advantages, how to choose the right system, and some famous examples.
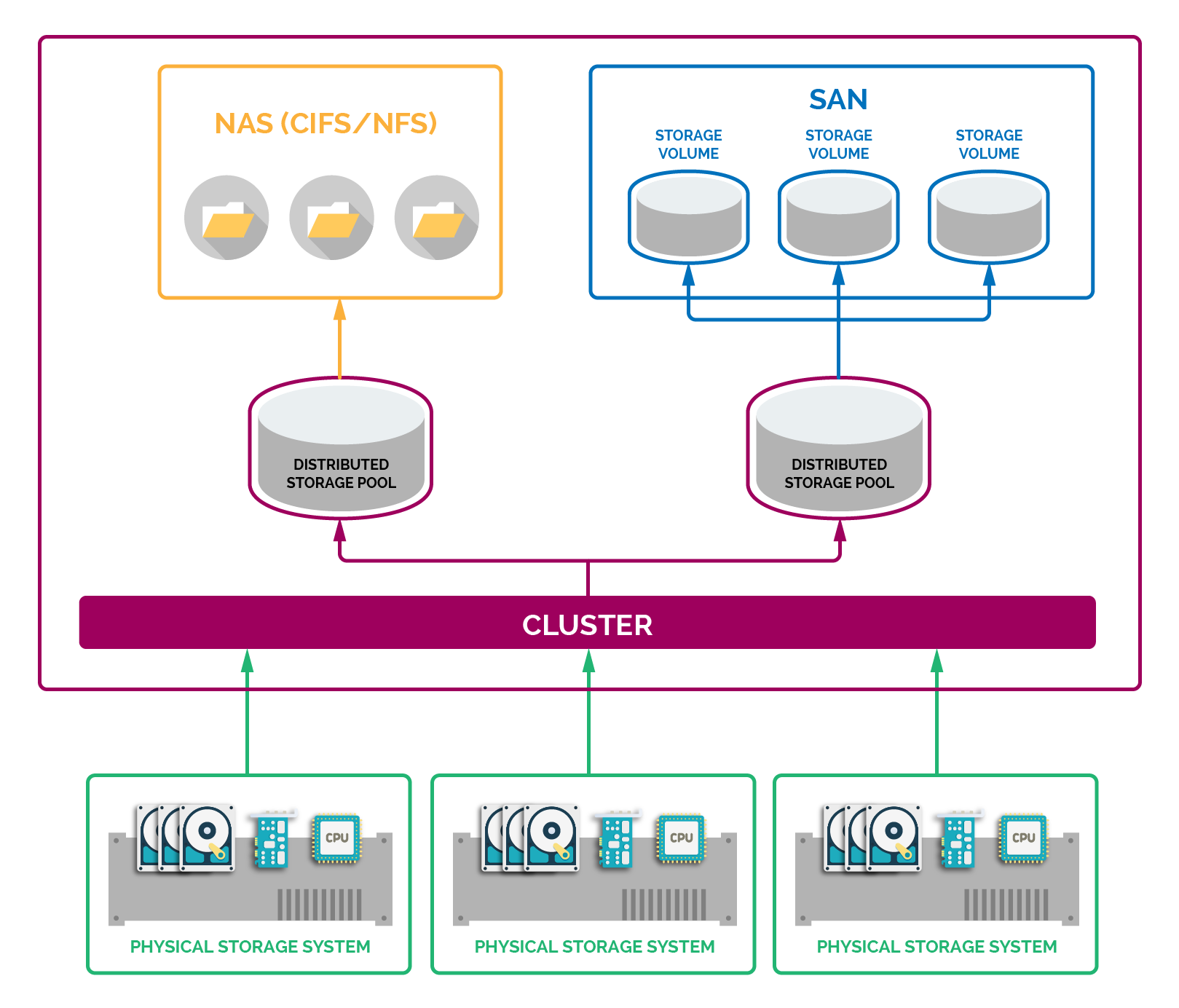
Source : BMC
Different Data Types for Distributed Storage
Distributed storage systems are built to effectively manage extensive spectrums of data variations – ranging from structured data that strictly adheres to a schema or model (such as relational databases or RDBMS), semi-structured data like XML/JSON files containing structured tags or markers to loose-format, high complexity unstructured data (often found in text, multimedia).
These streamlined systems accommodate many data types through specialized components. On the one hand, they handle traditional databases efficiently, utilizing their characteristic algorithms to synchronize data across geographically diverse nodes while maintaining strict ACID (Atomicity, Consistency, Isolation, Durability) properties required for transaction-oriented operations.
For file systems and object storage, the distributed storage arrangements synergistically integrate pertinent protocols dealing with file semantics, allowing scalable high-capacity conservatories for binary data objects. Such mechanisms facilitate immediate access to files or delivery of concurrent read and write operations via RESTful APIs, fueling high-performance computing (HPC) environments.
Parallelly, distributed key-value stores are capacitated to architect massive horizontally scalable storehouses for web-scale integers. They provide commendable low-latency performance for highly replicated, lightning-speed read/write endeavors. They support significant data operations with beneficent, paramount performance, such as real-time analytics, personalized content delivery, and caching.
Unlocking the Benefits of Distributed Storage
Distributed storage systems provide several advantages, including:
- Scalability: One undeniable advantage of distributed storage systems is their peerless capability for horizontal scaling. As your organization continues to create and accumulate data, these systems are designed to grow with you. Assets are allowed to expand across servers, rather than in a hierarchical manner, fostering an environment ready for extensive new data streams or increasing quantity of data cases.
- Fault-Tolerance: Built on the very concept of decentralization, distributed storage systems intelligently replicate data across multiple connected nodes (both within and across geographically dispersed locations) to inherently serve built-in redundancy. If one node encounters a problem or breaks down, the entire data stake is not jeopardized but can be resourced from other points in the network.
- Performance: Enhanced performance figures are consistently achieved through distributed storage due to the congruent delegation of tasks finely openly allocated across linked nodes. Each node operates independently in its mastered field, whereas chores, like read and write operations, get strikingly shared, effectively leading to positive combined enhancements and faster execution.
- Flexibility: Distributed storage architecture is hallmarked by a high degree of plasticity. The use-case agnostic storage design can ideally leverage everything ranging from serving high-performance computing demands via quick access to storage clusters, omnipresent requisites with geographically distributed data, low-latency data retrieval scenarios in OLTP (Online transaction processing) set-ups to fully ingrained analytic processing capabilities for deciphering voluminous valuable business insights.
Factors to Consider When Selecting Distributed Storage
Choosing the right distributed storage system depends on several factors, including:
- Data Requirements: Parameters such as the projected data size (including current volumes and growth estimates), the inherent structure of data (structured like SQL, semi-structured like SQL-NoSQL hybrids, or unformatted streams of data like log events), and the anticipated patterns of data interaction should underpin the decision-making process. For instance, it is essential to understand whether the system should cater to infrequent but complex data queries demanding high processing power or recurring and simple read-and-write operations requesting low latency delivery.
- Consistency Trade-offs: When deciding on infrastructural components, ascertain your application’s consistency requirements. Some systems vouch for strong consistency, aspiring to achieve ‘linearizability’ where every operation appears atomically and in a specific order, thereby ensuring stringent control and high data authenticity. On the other spectrum is ‘eventual consistency,’ a model championed by other systems that may initially tolerate temporary inconsistencies but guarantees ultimate data replication unity across nodes over a period.
- Performance and Scalability: It is recommended to investigate performance indicators of prospective systems meticulously. These include read and write latencies as they directly influence user experience and operational efficiency. Equally important is to assess the system’s ability to scale horizontally and ascertain if it can dynamically increase capacity by connecting several hardware or software entities to work symbiotically as a unified network. This capability guarantees sustained service even in the face of voluminous data accrual or high concurrent connection.
- Deployment Model: Pick the platform environment in alignment with your organization’s defined infrastructure preferences, operational needs, and enterprise strategy. You could opt for an on-premises deployment ensuring maximum control and potential compliance adherence, a cloud-based deployment capitalizing on scalability, simplicity, and cost-effectiveness, or a hybrid model, which effectively marries both on-premises and cloud components to optimize operational agility, cost, and performance dependencies while adhering to data locality regulation.
Exploring Distributed Storage Solutions
There are numerous distributed storage systems available, each catering to different use cases. Here are a few notable examples:
- Apache Hadoop Distributed File System (HDFS): HDFS is a widely used distributed file system designed for big data processing. It offers high fault tolerance, scalability, and compatibility with the Hadoop ecosystem.
- Amazon S3: Amazon Simple Storage Service (S3) is a popular object storage service that provides virtually unlimited scalability, durability, and low-cost storage for various applications.
- Apache Cassandra: Cassandra is a highly scalable, distributed database management system known for its ability to handle massive amounts of structured and unstructured data with high availability and fault tolerance.
- Google Cloud Storage: Google Cloud Storage offers a scalable and secure object storage service designed for storing and retrieving large amounts of data with strong consistency and global accessibility.
Embracing the Power of Distributed Storage Systems
Distributed storage systems have revolutionized the way organizations manage and store data. By offering scalability, fault tolerance, and performance, they provide robust solutions for modern data-intensive applications. When choosing a distributed storage system, it’s essential to consider factors such as data requirements, consistency trade-offs, performance, and deployment models. With the right strategy in place, organizations can unlock the full potential of their data infrastructure and drive innovation in today’s digital landscape.