In the Awe of Cloud Data Warehouse
Cloud data warehouse is ascending towards a global and more economic acceptance, and AWS already has their horse in the race – Amazon Redshift. Global data players trust Redshift’s architecture to integrate their data engineering, cx automation, and business intelligence tools. In a time when Seagate already reports that barely more than 30% of our data can be put to work as of now, the cloud data warehouse is our best bet to change that forever and for good.
Amazon Redshift is being used by organizations to assimilate data from multiple channels, including internal reports, marketing inputs, financial transactions, customer insights, partner interfaces, and much more, with astounding scalability. Moreover, it is reliable, durable, secure, and cost optimized.
Therefore, this article will take a closer look into the architecture of Amazon Redshift and discuss the benefit that this architecture serves.
The Inherited Architecture
Since its conception, the data warehouse has been through multiple refurbishments. We’ve had models like a virtual data warehouse, data mart, and enterprise data warehouse – each serving its own complexity domain, including reporting, analysis, research, enterprise decision support, data visualization, and more. We’ve also had schemas like snowflake and star schemas that serve the organization based on data integrity and data utilization requirements. Moreover, there have been multiple data loading methods like ELT (Extract Load Transform) and ETL (Extract Transform Load) as per the structuring needs of the organization. However, Amazon Redshift, even after uplifting the storage infrastructure for the cloud, seems to have inherited the basic cluster-node architecture. Let’s have a brief revision before moving the discussion forward.
The typical cloud data warehouse architecture for Amazon Redshift consists of the following elements:
- Clusters – This can be seen as the core enabler of the cloud data warehouse. The client tools and users essentially query and interact with the cluster through ODBC and JDBC connections. Clusters, as the name suggests, comprise a group of nodes which are computational units meant to process the data as per the client query demands.
- Leader Node – Each cluster typically has one node assigned for directly interacting with the client. The query is then divided and distributed among other nodes for further computation.
- Compute Nodes – The code compiled and assigned to these compute nodes is then processed and collected back for final aggregation to the result. Here are the primary parts of a compute node:
- Virtual CPU
- RAM
- Resizable Memory Partition Slices
A cluster’s storage capacity essentially depends on the number of nodes it is comprised of.
How does this architecture help Amazon Redshift to meet the scalability and performance needs? That is the question we would explore in this article in its subsequent sections.
Scalable Data Querying
The Amazon Redshift clients are connected with the client using ODBC (Open Database Connectivity) and JDBC (Java Database Connectivity) drivers. This makes them compatible with all the prime data engineering and data analytics tools that further serve the IoT edges, Business Intelligence tools, Data Engineering clients, etc.
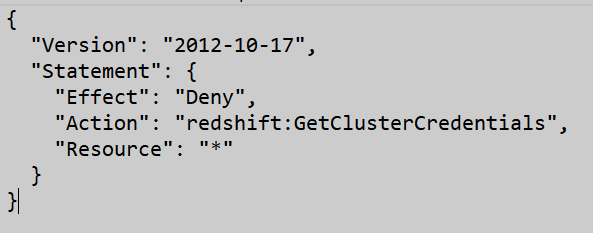
The cluster-node architecture holds several databases for Redshift that can be queried using the editor or console offered by AWS. These queries can be scheduled and reused as per the business requirements. The permission to these queries can be managed more easily since there are multiple compute nodes to process the queries. For instance, here’s the code to deny the permission for the GetClusterCredentials command using a custom policy.
Tighter Access and Traffic control
With the cluster node architecture, it is easy to route the traffic for access control and security. Amazon Redshift accomplishes this using Virtual private cloud (VPC). With a distributed architecture, the data flow control between Redshift clusters and the client tools gets tighter and more manageable. The COPY or UNLOAD command directed at the cluster is responded with the strictest network path to ensure uncompromised security. Some of the networks availablefor configuration for RedShift are:
- VPC endpoints: In case the traffic has to be directed to an Amazon S3 bucket for the same reason, this path seems most reasonable. It provides endpoint policies for access control on either side.
- NAT gateway: NAT or Network Address Translation gateway allows connection in other S3 buckets in other AWS regions and services in and out of the AWS Network. You can also configure SSH agent depending on the operation system
Multilevel security
The cluster-node architecture allows the security policies to work on multiple levels, strengthening the data security.
- Cluster Level: Security groups can be established to control the access to clusters in classless inter-domain routing and authorization. Additional policies can be set up for the creation, configuration, and deletion of the clusters.
- Database Level: Access control can be extended to the read and write for individual database objects like tables and views. The DDL and DML operations are also controlled to ensure that the mission critical data doesn’t fall into wrong or loose hands.
- Node Connection Authentication: The clients connected with ODBC and JDBC drivers can be authenticated for their identity using a single sign-on.
- Network Isolation: As we saw before, Redshift offers virtual private clouds to ensure that the networks are logically isolated and more secure for the cloud warehouse infrastructure. These isolated networks control the inbound traffic and allow only certain IPs to send requests and queries.
Easy Clusters Management and Maintenance
Policies are set for Cluster maintenance and management that ensure regular cluster upgrading and performance checks. Regular maintenance windows can be set for the clusters to perform check-ups on them and ensure there are no deviations in their operations. These policies are determined based on:
- Maintenance Scheduling – You can decide maintenance windows during which the cluster won’t be operational and will be undergoing maintenance checks. Most of the vendors offer default maintenance windows which can be rescheduled as per your requirements.
- Cluster Upgrade – You might not always want your clusters to run on the most recent approved versions, or they can stick with the previous releases. Amazon redshift allows an option of preview that would help you understand your clusters’ expected performance for the new upgrade.
- Cluster Version Management – You can upgrade to the latest cluster version or roll-back to a previous one. The performance of the cluster version should be in line with your business requirements.
Conclusion
Data warehouses were borne out of the necessity of making the data to work for our business rather than lying stale in our servers. Amazon Redshift, like many other vendors, took the concept further and evolved the traditional data warehouse architecture for cloud benefits. The cluster-node architecture isn’t a much big leap from the original Data Warehouse architecture. This makes it easier to manage, maintain and protect. With data pouring in from our social media interactions, project reports, workforce feedbacks and customer experience innovations, it will be of great disadvantage not to engage it. The clouds are ready to hold dense data volumes, all we need is a little (Red)Shift.